浅入浅出kafka
wikipedia的解释
弗兰兹·卡夫卡,生活于奥匈帝国统治下的捷克德语小说家,本职为保险业职员。主要作品有小说《审判》、《城堡》、《变形记》等。
kafka官网的解释
Kafka是由Apache软件基金会开发的一个开源
流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据。
两个kafka有一个共同特点: 很会写
消息系统
实现低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能,成为异步RPC的主要手段之一。
什么是消息系统


一个最简单的消息系统:producer发送消息给broker(消息队列),broker持有数据,在合适的时机发送给consumer,consumer确认后,broker删除消息数据。
扩展概念
- 消息队列模型 sender -> queue -> receiver
- 发布/订阅模型 publish -> topic -> subscribe
- 消息投递 push
- 消息拉取 pull
什么时候使用消息系统



适合场景
- 业务解耦,领域更清晰。区分业务核心系统
- 最终一致性(反之,强一致性,需要接收方回调确认,同步RPC更合适)
- 广播,1 VS N,稳定上游服务
- 错峰流控,拉平峰值,避免木桶
- 日志同步
不适合场景
- 强事务保证
- 对延迟敏感,需要实时响应
kafka好在哪
吞吐量/延时
- 吞吐量: 每秒能够处理的消息or字节数。
- 延时: 客户端发送请求、服务端处理请求并发送相应给客户端。
延时越低,吞吐越高?
通常情况下,我们认为延时越低,单位时间可以处理的请求变多,所以吞吐量增加。但是两者并不是正相关关系。
e.g. kafka处理一条消息需要花费2ms,吞吐量为1000/2=500。如果通过batch,批量发送,每8s发送一次600条,延时=2ms+8ms=10ms,600(1000/10)=60000。*
消息持久化
保存在硬盘,不会丢失,可以重放。and 性能很高!!! 后面聊原因。
负载均衡和故障转移
多副本、多分区,保障高可用。
伸缩性
自身无状态,方便扩展。
名词解析
- message -> 消息
- broker -> kafka服务器
- topic -> 主题,逻辑概念。定义一类消息,一个消息内容体
- partition -> 分区,消息实际存储的物理位置。保存在磁盘中的有序队列,维护offset。
- replica -> 副本(partition)。分为leader replica 和 follower replica。和Master-Slave不同,follower只从leader同步数据,不提供读写。只有在leader挂了之后,才会选举follower作为leader提供服务。kafka保障同一个partition的replica在不同的broker,否则无法提供故障转移。同一个topic可以有不同的leader,同一个topic+partition只有一个leader。
- ISR(is-sync replica) -> 同步副本集合。如果follower延迟过大,会被踢出集合,追赶上数据之后,重新向leader申请,加入ISR集合。并不是所有的follower都可以成为leader,ISR集合中的follower可以竞选leader。通过replica.lag.time.max.ms(默认10s)设置follower同步时间,通过RetchRequest(offset)同步leader信息。
- offset -> 位移、偏移量
- producer -> 生产者
- consumer -> 消费者
- group -> 组。通过维护各group的offset,每条消息只会被发送到同一个group下的一个consumer,实现不同模型。
- controller -> 控制器。选举broker作为controller,管理和协调kafka集群,和zookeeper通信。
- coordinator -> 协调者。用于实现成员管理、消费分配方案制定(rebalance)以及提交位移等,每个group选举consumer作为协调者。
topic、partition和broker
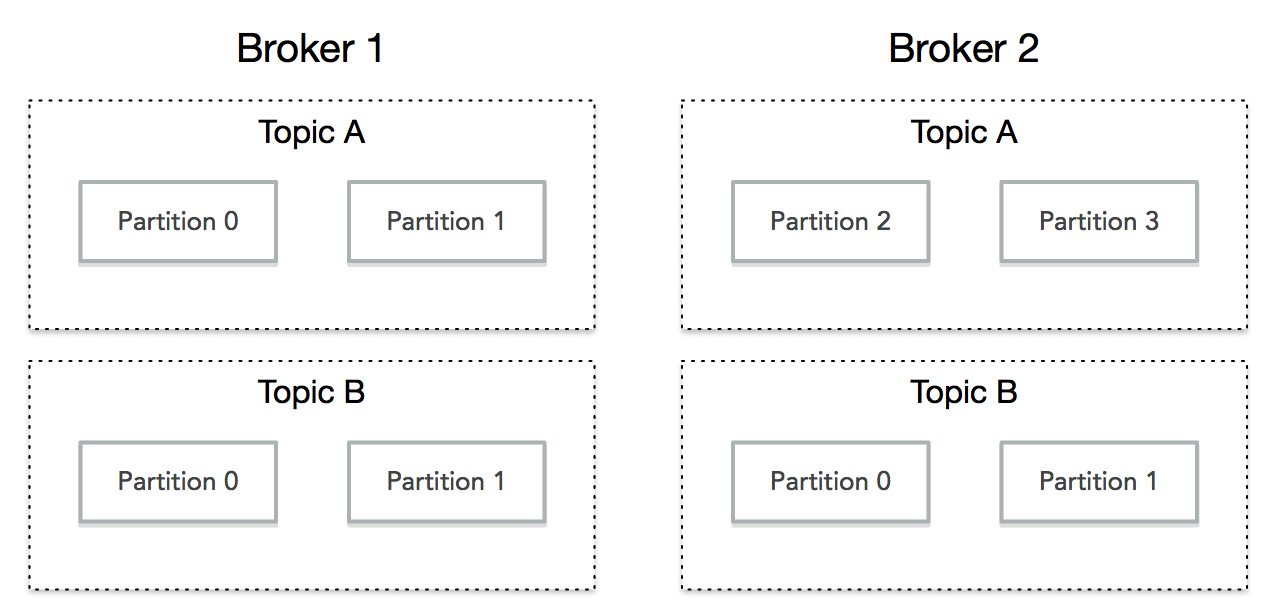
- 同一个topic可以在不同broker上维护不同的分区(负载均衡)
- 同一个topic可以在不同broker上维护同一个分区(冗余机制,故障转移)
offset同步及水位
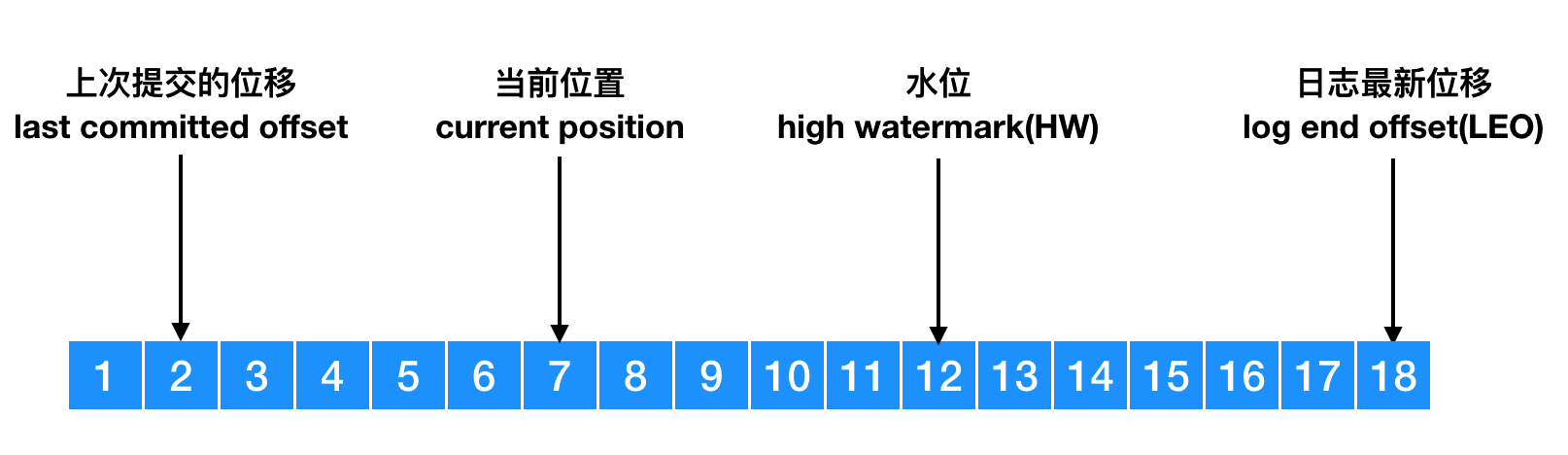
- 上次提交的位移:group确认的offset
- 当前位置:读取后,未提交
- HW:ISR确认已同步后,leader增加HW。
- LEO: leader接收到的最新一条producer发送的数据
- consumer只能消费到HW,未同步给所有ISR成员的消息无法消费
- leader保存 LEO、HW和remote LEO, min(LEO, remote LEO) 更新HW
- follower轮询leader,purgatory暂存请求,500ms
- 新版本epoch保存leader变更版本,维护kv (epoch, offset)
group
- 一个group有一或多个consumer
- 一个消息可以发送给多个group
kafka高性能的秘密
顺序写?

网上的教程经常看到介绍,写入耗时主要集中在磁头寻道和盘片旋转,而数据传输速度很快。kafka采用了顺序写,所以效率高。不免有些疑问:
- 顺序写性能高,为什么还有随机写?
- 磁盘不会被占用,每次写入都需要寻道、旋转,那么顺序写的优势在哪?
原因
- 因为写入的是不同的文件,占用连续的page。顺序写,不能修改。
- 增加前提:一次写入一个文件且文件足够大。
所以本质原因在于追加写,”每个partition是一个文件”。
读取时,识别顺序写,会进行预读。
PageCache
- Kafka不会每次都写磁盘,而是写入分页存储PageCache就认为producer成功。
- 操作系统决定什么时候将PageCache写入磁盘(flush)。增加flush时间间隔,可以提升吞吐
- flush时为顺序写入,不会有额外的性能损耗。
- 读取时,优先读取PageCache。
PageCache为缓存,数据会不会丢失?
因为是操作系统管理,所以kafka进程挂了,数据不会丢失。如果操作系统掉电。。。依靠副本
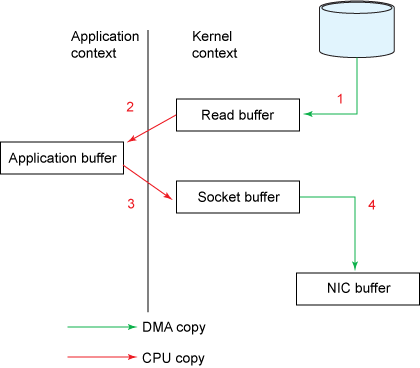
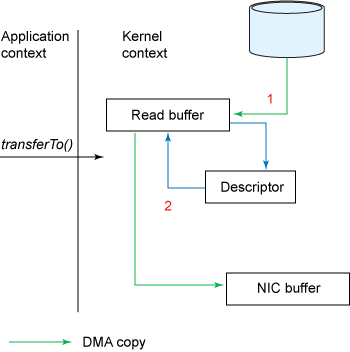
Zero Copy
依赖于linux系统的sendfile函数,针对java,则通过FileChannel.transferTO
partition
- leader针对partition而不是broker
- partition不是一个文件而是一个文件夹
- partition是我们能操作的最小概念
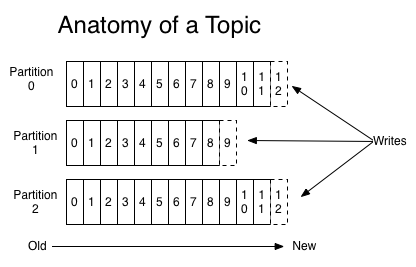
如果一直追加会导致文件过大,不便于使用(读写)和维护(删除旧数据),kafka为此采用了几种措施
- 区分segment
- 增加索引,包括index和timeindex
segment
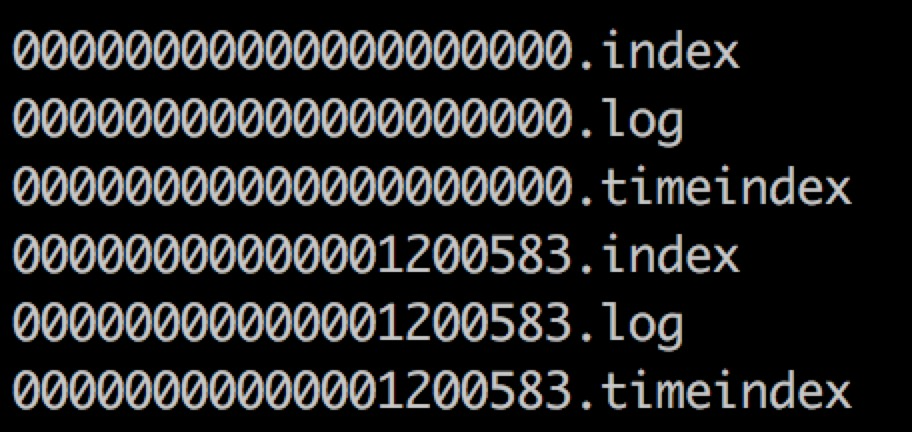
segment=log+index+timeindex- 命名规则为segment文件最后一条消息的offset值。
- log.segment.bytes 日志切割(默认1G)
index和timeindex

- index,位移索引,间隔创建索引指向物理偏移地址。间隔通过log.index.interval.bytes设置,默认4MB。
- timeindex,时间索引,为满足时序型统计需求。
1 |
|
索引文件预分配空间,切分时裁剪。
p.s. producer发送消息时,可以指定时间戳。如果机器时区不同,或者retry、网络延时等导致时间混乱,按照时间索引进行查询时,导致查询不到消息。?? 时间会在发送时获取本机时间
1 | long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp(); |
producer
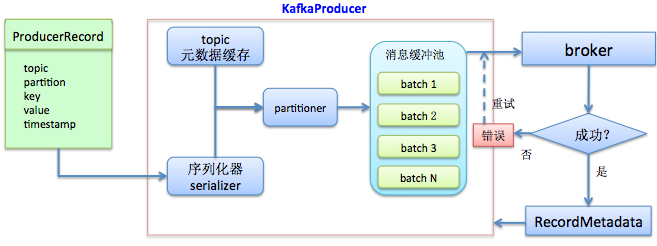
producer配置
通过配置文件了解细节
- bootstrap.servers 指定其中一个,会自动找到leader,但是如果指定的机器挂了,无法切换
- acks 0, 1, all|-1。 0表示无需确认,1表示leader确认,-1表示所有ISR确认。
- buffer.memory 缓存消息的缓冲区大小32MB,过小会影响吞吐。写入速度超过发送速度,停止&等待IO发送,still追不上会报错。
- compression.type 开启压缩,提升IO吞吐,增加CPU压力。需要看服务器是IO密集型or计算密集型。 属性 0: 无压缩,1: GZIP,2: Snappy,3: LZ4
- retries 重试,屏蔽网络抖动or leader选举 or NotController,导致消息重复发送。详细参见
RetriableException - retry.backoff.ms 重试间隔
- batch.size 批量发送大小,默认16KB,增加可提升吞吐
- linger.ms 发送时间,默认为0,立即发送,不判断batch.size大小。
- max.request.size 消息大小,因为存在header等,实际大小大于消息本身
- request.timeout.ms 超时时间,默认30s。broker给producer反馈
- partitioner.class
- key.serializer & value.serializer
- interceptor.classes 自定义拦截器
自定义serializer
1 | public class FastJsonSerializer implements Serializer { |
自定义partitioner
1 | public class AbsPartitioner implements Partitioner { |
自定义分区策略 机器人发送到同一个partition,为了快速响应真实用户。如果只是为了均匀分布,不需要指定key(和旧版本不同)。
如果未指定key,会通过轮询,避免skewed
1 | public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { |
producer拦截器
1 | public class ProducerLogInterceptor implements ProducerInterceptor<String, Object> { |
100% 送达配置 | 无消息丢失配置
通过配置替换 send().get()
- max.block.ms=999999
- acks=-1
- retries=999 不会重试非RetriableException异常
- max.in.flight.requests.per.connection=1 发送未响应请求的数量
- KafkaProducer.send(record,callback)
- clonse(0)
消息内容
| CRC | 版本号 | 属性 | 时间戳 | key长度 | key内容 | value长度 | value内容 |
|---|---|---|---|---|---|---|---|
| 4B | 1B | 1B | 8B | 4B | n | 4B | n |
Consumer
group保存位移offset,替换zookeeper保存(/consumers/groupid/offsets/topic/partition节点)。checkpointing定期从consumer到broker对offset进行持久化。(log.flush.offset.checkpoint.interval.ms 默认60s)
offset格式=map(groupId+topic+partition, offset)
为什么不用zookeeper保存?
- zookeeper不擅长频繁写(强一致性)
为什么不用broker保存?
- 增加应答机制,确认消费成功,影响吞吐
- 保存多个consumer的offset,数据结构复杂
1 | /** |
Consumer配置
session.timeout.ms协调者(coordinator)检测失败的时间,踢出consumer rebalanceheartbeat.interval.ms如果需要rebalance,会在心跳线程的response中set rebalance_in_progress,心跳线程间隔。必须小于session.timeout.msmax.poll.interval.msconsumer处理逻辑最大时间 & consumer启动选举coordinator时间auto.offset.resetearliest|lastest 更换group后,重新消费。 默认lastestenable.auto.commitfalse 手动提交位移auto.commit.interval.ms自动提交位移时间间隔fetch.max.bytes如果消息很大,需要手动设置 50 * 1024 * 1024max.poll.records单次调用返回的消息数 500connections.max.idle.ms默认9分钟,推荐-1。不关闭空闲连接,周期性请求处理时间增加。partition.assignment.strategypartition分配策略, 默认 RangeAssignor
partition分配策略
每个partition分配给一个consumer。
e.g. 如果一个group订阅一个topic,一个topic有100个partition,一个group有5个consumer。则每个consumer消费20个partition
partition分配策略,继承AbstractPartitionAssignor自定义策略规则,加权重等。自带分配规则:
- range 分区顺序排列、分组、分配给consumer
- round-robin 分区顺序排列, 轮询consumer,读取分区
- sticky 基于历史分配方案,避免数据倾斜
1 | public class RangeAssignor extends AbstractPartitionAssignor { |
误解
使用过程中对kafka consumer的一些误解
误解1
poll(long timeout)和max.poll.records按照时间或者消息记录数,控制每次获取消息。
poll表示轮询,使用poll而不是pull,并不需要wakeup。所以可以使用poll(Long.MAX_VALUE),每次数据流准备好后,会返回并进行业务处理。
误解2
“consumer只能订阅一个topic。”
1 | consumer.subscribe(Pattern.compile("kafka.*")) |
误解3
“commitSync同步提交,阻塞消费。commitAsync异步提交,不阻塞消费。”
commitSync和commitAsync都会阻塞poll,因为在poll执行时轮询时会判断commit状态。commitAsync不阻塞业务处理后续方法执行。
1 | void invokeCompletedOffsetCommitCallbacks() { |
EOS(Exactly-once Semantics)
- at most once 最多一次,消息可能丢失,但不会被重复处理。获取消息后,先commit,然后业务处理。
- at least once 最少一次 消息不会丢失,但可能被处理多次。获取消息后,先业务处理,然后commit。
- exactly once 会被处理且只会被处理一次
消费指定partition
自定义分配策略?不需要,可以通过assign指定topic partition
1 | consumer.assign(Collections.singletonList(new TopicPartition(TOPIC, partition))); |
- assign + subscribe 冲突错误
java.lang.IllegalStateException: Subscription to topics, partitions and pattern are mutually exclusive - assign + assign 后一个生效
- 2个consumer assign同一个partition 消费两次
- 一个consumer assign 一个consumer subscribe, rebalance 踢出assign
控制提交分区offset
Map<TopicPartition, OffsetAndMetadata> offsets 控制提交分区offset,细粒度
1 | consumer.commitSync(Collections.singletonMap(tp, offset)); |
rebalance
通过状态机模式管理。
rebalance触发条件
- consumer加入、退出、崩溃
- topic发生变更,如正则匹配,增加topic
- 分区发生变动
- 消费处理超时
rebalance协议
- joinCroup 请求
- SyncGroup 请求,group leader 同步分配方案
- Heartbeat 请求 向coordinator汇报心跳
- LeaveGroup 请求
- DescribeGroup 查看组信息
rebalance优化
- 因为rebalance系统开销大,需要合理设置request.timeout.ms、max.poll.records 和 max.poll.interval.ms 减少rebalance次数。
- rebalance generation 标识 rebalance,每次+1, 延迟提交offset会被group拒绝 ILLEGAL_GENERATION
rebalance细节
- 收集join consumer,选取leader,同步给coordinator。 leader 负责分配
- 同步更新分配方案,发送SyncGroup请求给coordinator,每个consumer都发送,coordinator接受leader的方案,分配,返回response
1 | def handleJoinGroupRequest(request: RequestChannel.Request) { |
多线程消费
自己实现缓存区,批量执行及确认consumer.commitSync
- 多consumer thread 效率高,单独offset。 缺点:受限于topic分区数,broker压力大,rebalance可能性大
- 单consumer 多handler thread ,获取和处理节藕,伸缩性好。难于管理分区内消息顺序,位移提交困难,处理不当导致数据丢失。
其他
日志留存
- log.retemtopm.{hours|minutes|ms}
- log.retention.bytes 字节 默认-1
- 当前日志段不会清除
- 和日志最近修改时间比较、比较记录时间戳
暂停consumer消费
e.g. 消费逻辑为调用三方接口,如果三方接口不稳定,需要关闭一段时间。
- 暂停
consumer.pause(consumer.assignment()); - 启动
consumer.resume(consumer.assignment());
compaction
- 订阅binlog see canal
- 高可用日志化
manager指定lisnterners
因为kafka内部使用全称域名,不统一,导致无法获取元数据
生产环境
- 优雅的启动和关闭(Spring生命周期)
- offset跳过与重放